
In the previous blog posts about predicting football results using Poisson regression I have mostly ignored the fact that the data points (ie matches) used to fit the models are gathered (played) at different time points.
In the 1997 Dixon and Coles paper where they described the bivariate adjustment for low scores they also discussed using weighted maximum likelihood to better make the parameter estimates reflect the current abilities of the teams, rather than as an average over the whole period you have data from.
Dixon and Coles propose to weight the games using a function so that games are down weighted exponentially by how long time it is since they were played. The function to determine the weight for a match played is
where t is the time since the match was played, and \(\xi\) is a positive parameter that determines how much down-weighting should occur.
I have implemented this function in R, but I have done a slight modification from the one from the paper. Dixon and Coles uses “half weeks” as their time unit, but they do not describe in more detail what exactly they mean. They probably used Wednesday or Thursday as the day a new half-week starts, but I won’t bother implementing something like that. Instead I am just going to use days as the unit of time.
This function takes a vector of the match dates (data type Date) and computes the weights according to the current date and a value of \(\xi\). The currentDate argument lets you set the date to count from, with all dates after this will be given weight 0.
DCweights <- function(dates, currentDate=Sys.Date(), xi=0){
datediffs <- dates - as.Date(currentDate)
datediffs <- as.numeric(datediffs *-1)
w <- exp(-1*xi*datediffs)
w[datediffs <= 0] <- 0 #Future dates should have zero weights
return(w)
}
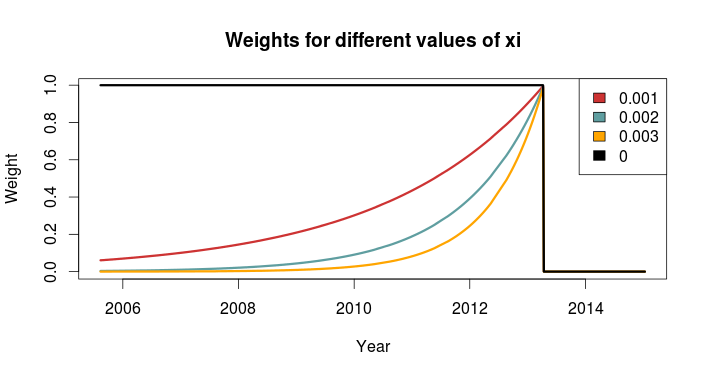
We can use this function to plot how the much weight the games in the past is given for different values of \(\xi\). Here we see that \(\xi = 0\) gives the same weight to all the matches. I have also set the currentDate as a day in April 2013 to illustrate how future dates are weighted 0.
To figure out the optimal value for \(\xi\) Dixon and Coles emulated a situation where they predicted the match results using only the match data prior to the match in question, and then optimizing for prediction ability. They don’t explain how exactly they did the optimizing, but I am not going to use the optim function to do this. Instead I am going to just try a lot of different values of \(\xi\), and go for the one that is best. The reason for this is that doing the prediction emulation takes some time, and using an optimizing algorithm will take an unpredictable amount of time.
I am not going to use the Dixon-Coles model here. Instead I am going for the independent Poisson model. Again, the reason is that I don’t want to use too much time on this.
To measure prediction ability, Dixon & Coles used the predictive log-likelihood (PLL). This is just the logarithm of the probabilities calculated by the model for the outcome that actually occurred, added together for all matches. This means that a greater PLL indicates that the actual outcomes was more probable according to the model, which is what we want.
I want to use an additional measure of prediction ability to complement the PLL: The ranked probability score (RPS). This is a measure of prediction error, and takes on values between 0 and 1, with 0 meaning perfect prediction. RPS measure takes into account the entire probability distribution for the three outcomes, not just the probability of the observed outcome. That means a high probability of a draw is considered less of an error that a high probability of away win, if the actual outcome was home win. This measure was popularized in football analytics by Anthony Constantinou in his paper Solving the Problem of Inadequate Scoring Rules for Assessing Probabilistic Football Forecast Models. You can find a link to a draft version of that paper on Constantinou’s website.
I used data from the 2005-06 season and onwards, and did predictions from January 2007 and up until the end of 2014. I also skipped the ten first match days at the beginning of each season to avoid problems with lack of data for the promoted teams. I did this for the top leagues in England, Germany, Netherlands and France. Here are optimal values of \(\xi\) according to the two prediction measurements:
| PLL | RPS | |
|---|---|---|
| England | 0.0018 | 0.0018 |
| Germany | 0.0023 | 0.0023 |
| Netherlands | 0.0019 | 0.0020 |
| France | 0.0019 | 0.0020 |
The RPS and PLL mostly agree, and where they disagree, it is only by one in the last decimal place.
Dixon & Coles found an optimal value of 0.0065 in their data (which were from the 1990s and included data from the top four English leagues and the FA cup), but they used half weeks instead of days as their time unit. Incidentally, if we divide their value by the number of days in a half week (3.5 days) we get 0.00186, about the same I got. The German league has the greatest optimum value, meaning historical data is of less importance when making predictions.
An interesting thing to do is to plot the predictive ability against different values of \(\xi\). Here are the PLL (adjusted to be between 0 and 1, with the optimum at 1) for England and Germany compared, with their optima indicated by the dashed vertical lines:

I am not sure I want to interpret this plot too much, but it does seems like predictions for the German league are more robust to values of \(\xi\) greater than the optimum, as indicated by the slower decline in the graph, than the English league.
So here I have presented the values of \(\xi\) for the independent Poisson regression model, but will these values be the optimal for the Dixon & Coles model? Probably not, but I suspect there will be less variability between the two models than between the same model fitted for different leagues.
Could you show how you could include this into the existing Dixon and Coles model you have produced please? I’m not sure how you add it in and I’m interested to see the results.
It is really simple actually, just multiply the weights with the log likelihood for each match, before you sum them together. You can replace the original log likelihood function with this:
DClogLikWeighted <- function(y1, y2, lambda, mu, rho=0, weights=NULL){ #rho=0, independence #y1 home goals #y2 away goals loglik <- log(tau(y1, y2, lambda, mu, rho)) + log(dpois(y1, lambda)) + log(dpois(y2, mu)) if (is.null(weights)){ return(sum(loglik)) } else { return(sum(loglik*weights)) } }It should be obvious, but anyway: Give your weights (calculated by the DCweights function, for example) to the weights argument. If you don’t give it any weights it will give equal weight to all matches, i.e. the same results as before.
Hi, there. I have read many of your article. But I don’t understand this one. So, do you mean I should type “DCweights” instead of “NULL” ?
I did it. I put the function DCweights right after the function tau, and changed the DCloglik to the function DCloglikWeighted and also the NULL to DCweights.
It gave me this:
> HomeWinProbability
[1] NA
> DrawProbability
[1] NA
> AwayWinProbability
[1] NA
please help.
it gave me this:
Error in loglik * weights: non-numeric argument of a binary operator
You should compute the weights first, for example like this:
myweights <- DCweights(dates, xi=0.0018) This creates a vector with the weights that you can pass to the DClogLikWeighted function: DClogLikWeighted(...., weights=myweights)
However, how to input dates from csv file? Should we make a matrix like attack.p in DCoptimFn?
I did it that way but it doesn’t work.
DCmodelData <- function(df){
hm <- model.matrix(~ HomeTeam – 1, data=df, contrasts.arg=list(HomeTeam='contr.treatment'))
am <- model.matrix(~ AwayTeam -1, data=df)
team.names <- unique(c(levels(df$HomeTeam), levels(df$AwayTeam)))
ax = model.matrix(~ Date -1,data=df)
return(list(
homeTeamDM=hm,
awayTeamDM=am,
homeGoals=df$FTHG,
awayGoals=df$FTAG,
dates=ax,
teams=team.names
))
}
DCoptimFn <- function(params, DCm){
home.p <- params[1]
rho.p <- params[2]
nteams <- length(DCm$teams)
ndates <- length(DCm$dates)
attack.p <- matrix(params[3:(nteams+2)], ncol=1)
defence.p <- matrix(params[(nteams+3):(nteams+2+nteams)], ncol=1)
da <- matrix(params[(nteams+nteams+3):length(DCm$dates)],ncol=1)
lambda <- exp(DCm$homeTeamDM %*% attack.p + DCm$awayTeamDM %*% defence.p + home.p)
mu <- exp(DCm$awayTeamDM %*% attack.p + DCm$homeTeamDM %*% defence.p)
dates <- (DCm$dates %*% da)
xi <-0.0018
datediffs <- as.Date(dates,"%d%b%Y") – as.Date("2013-12-30")
datediffs <- as.numeric(datediffs *-1)
w <- exp(-1*xi*datediffs)
w[datediffs <= 0] <- 0 #Future dates should have zero weights
return(
DClogLikWeighted(y1=DCm$homeGoals, y2=DCm$awayGoals, lambda, mu, rho.p, w) * -1
)
}
You don’t really have to do anything special with the dates, just pass the column to the as.Date function, with the appropriate format argument. This is what is already done in the command that creates the datediff variable. You don’t have to use the model.matrix argument or do any matrix multiplication. So your da and (DCm$dates %*% da) stuff is not really needed. In the way you have set it up you can just do like this in the DCmodelData function:
ax <- df$Date
I think I am able to do it. Thank you so much.
I have problems to compute THIS:
myweights <- DCweights(dates, xi=0.0018)
It gives me this error:
Error in DCweights(dates, xi = 0.0018) : 'dates' object not found
It says the ‘dates’ object not found, which means you have not defined a variable called ‘dates’.
Would a Pareto decay model not be more representative of the recent value of the team strengths? Exponential decay places a lot of emphasis on form, which doesn’t take into account the varying strengths of opposition?
Have you thought about modelling adjustments for strength of schedule ?
I have been thinking a bit about other possible weighting schemes, and I will definitely look into the Pareto function. Thanks for the tip!
One thing I tried was incorporating seasons into the weights. The idea was that the current season should count more than the previous ones, since I thought data from 5 months back would less informative if that was in the previous season than in the current one. What I did was just multiplying the weights in the previous seasons by a number less than 1 (and adjusting the xi parameter a bit), but at least for the Premier League it didn’t improve the predictions.
I think these regression models incorporate strength of schedule pretty good already, since the parameter estimates relies on all the data. I am not even sure the model could not incorporate strength of schedule, since if there were two groups of teams where no team in one group had played any team in the other group, I think the model would be unidentifiable. I have been thinking about looking into the “connectedness” between groups of teams (i.e. from different leagues) some time in the future.
Did you find that adding the time weightings yielded more accurate predictions vs the independent Poisson regression model with the Dixon and Coles low scoring adjustment?
I haven’t done any extensive testing of the different models, so I am not quite sure. I hope to get around to it sometime in the near future.
I get 0 as a weight for every single past match using your code. Is that expected?
Ignore the comment! I have sorted it out! Working as expected.
Just out of curiosity (I know you didn’t intend to maximise xi within the function because it takes time), but how would you go about it?
I just tried every value of xi between 0 and 0.0030, incremented by 0.0001 (R command: seq(0,0.0030, 0.0001)). Then I calculated the RPS for all 31 values of xi and found which value of xi gave the smallest one.
I also wondered how you implemented that. If I understood correctly, you have to refit the model each matchday and compute the probability of each outcome. Then you have to do the whole process for different values of xi and compare which xi yields the highest PPL. But there is no chance for me to see an easy implementation of that <.<
Yes that’s correct. You have to do this to get a realistic prediction. You should fit the model including the most recent data, and not having any future data. The implementation of that requires two loop constructs. The inner loop iterates over all match dates and does the model fitting and predictions, the outer loop goes over all values of xi.
Hey sorry for the late reply but really like the blog thanks! How do you optimize the function (model fitting) without using the optim function? At the moment I am optimizing for each game within the season (so 380 optim usages) and then adding the prediction for that game from the matrix just to calculate the value for one value of Xi?
If you are doing leave-one-out tuning you have to fit the model for each game. There is no way around. Yes it is time consuming. You might want to take a look at this post, which should speed things up.
http://opisthokonta.net/?p=927
Thanks for the reply! I’ve been doing it in gameweeks to try and speed it up, so predicting all 10 games in each gameweek at once using the data up until that gameweek. I just ran it for 2 seasons using a third season behind to give some data for the early games but it’s giving me pretty erratic values for Xi. I know it probably needs more data but can you see any issue with the code?
england %>%
filter(Season %in% c(2010, 2011, 2012), tier==1) %>%
mutate(home=as.character(home), visitor=as.character(visitor)) -> england_2010_12
england %>%
filter(Season %in% c(2011, 2012), tier==1) %>%
mutate(home=as.character(home), visitor=as.character(visitor)) -> england_2011_12
england_2010_12 <- england_2010_12[order(as.Date(england_2010_12$Date)),]
england_2011_12 <- england_2011_12[order(as.Date(england_2011_12$Date)),]
all_teams <- sort(unique(c(england_2010_12$home, england_2010_12$visitor)), decreasing = FALSE)
n_teams <- length(all_teams)
parameter_list <- list(attack = rep(0.2, n_teams), defence = rep(-0.01, n_teams-1), home=0.1,rho=0.00)
names(parameter_list$attack) <- all_teams
names(parameter_list$defence) <- all_teams[-1]
tau <- Vectorize(function(xx, yy, lambda, mu, rho){
if (xx == 0 & yy == 0){return(1 – (lambda*mu*rho))
} else if (xx == 0 & yy == 1){return(1 + (lambda*rho))
} else if (xx == 1 & yy == 0){return(1 + (mu*rho))
} else if (xx == 1 & yy == 1){return(1 – rho)
} else {return(1)}
})
dates <- england_2010_12$Date
DCweights <- function(dates, currentdate, xi=0){
datediffs <- dates – as.Date(currentdate)
datediffs <- as.numeric(datediffs *-1)
w <- exp(-1*xi*datediffs)
w[datediffs <= 0] <- 0
return(w)
}
Xi <- seq(0,0.003,0.0002)
resultprob <- rep(0, length(Xi))
for (u in 1:length(Xi)){
for (i in 1:76) {
myweights <- DCweights(as.Date(dates), currentdate=as.Date(england_2010_12$Date[i*10])+1, xi=Xi[u])
optim_res <- optim(par = unlist(parameter_list), fn=DCloglikweighted,
goals_home = england_2010_12$hgoal,
goals_visitor = england_2010_12$vgoal,
team_home = england_2010_12$home,
team_visitor = england_2010_12$visitor,
param_skeleton=parameter_list,
weights=myweights,
method = "Nelder-Mead", hessian = "FALSE")
parameter_estweight <- relist(optim_res$par, parameter_list)
parameter_estweight$defence <- c( sum(parameter_estweight$defence) * -1, parameter_estweight$defence)
names(parameter_estweight$defence)[1] <- names(parameter_estweight$attack[1])
for (j in 1:10) {
k <- j+(i-1)*10
lambda <- exp(parameter_estweight$home + parameter_estweight$attack[england_2011_12$home[k]] +parameter_estweight$defence[england_2011_12$visitor[k]])
mu <- exp(parameter_estweight$attack[england_2011_12$visitor[k]] +parameter_estweight$defence[england_2011_12$home[k]])
probability_matrix <- dpois(0:maxgoal, lambda) %*% t(dpois(0:maxgoal, mu))
scaling_matrix <- matrix(tau(c(0,1,0,1), c(0,0,1,1), lambda, mu, parameter_estweight$rho), nrow=2)
probability_matrix[1:2, 1:2] <- probability_matrix[1:2, 1:2] * scaling_matrix
ifelse(england_2011_12$result[k] == "H", resultprob[u] <- resultprob[u]+log(sum(probability_matrix[lower.tri(probability_matrix)])),
ifelse(england_2011_12$result[k] == "D", resultprob[u] <- resultprob[u]+log(sum(diag(probability_matrix))),
resultprob[u] <- resultprob[u] + log(sum(probability_matrix[upper.tri(probability_matrix)]))))
}
}
Thanks so much really enjoying work with the code!
You have hard coded in a lot on the indexing, which introduce a huge potential for bugs. I would rather than using game weeks instead go by date, and explicitly subset the training data by date. It looks like you don’t actually do any subsetting of the data in the loop. If you rely on the DCweight function to weight future games to 0 instead of subsetting, that seems like a potential source of error if you set the currentdate as the first date of the game week. And also, why don’t you use the goalmodel package I made?
Thanks for the reply – how would you go about subsetting the data efficiently? I tested the weights and it seemed to hold but you’re right it’s very messy. I was hoping to investigate the model, by seeing if the predictive capacity increased gameweek by gameweek, and then also by introducing a Pareto distribution instead of Exponential. From initial testing the former doesn’t seem to occur but I am concerned about bugs in the code. Have you looked into how else you might modify the model? I wanted to try and put in live stochastic parameters but wasn’t sure how I would go about implementing this
What sort of parameters are you thinking about? I have done a lot of different analyses and modifications to this type of models, just read some of the other posts on this blog. The simples way to subset the data is to just use the filter function in dplyr, and do something like filter(Date <= current_date) or something.
I was thinking of using the Pareto distribution instead of the exponential, but this would involve optimizing over two parameters in the distribution rather than just the one for the exponential – why I wanted to make sure I could get this to work first! Thank you very much for the tip on filtering by date, I didn’t know you could do that and it’s a much better method. Have you thought about implementing the Pareto?
Sorry I’ve tried to implement the dates system but am still getting very erratic values for the log of the probabilities. I am now doing this for fortnights through the season (omitting the first fortnight). Should I be putting in dates to the optim function or the full england_2009_12 data set? Also which algorithm do you use – I know Nelder Mead can converge to local results but BFGS seems to have some issues and takes far longer. Thanks again.
Xi <- seq(0,0.003,0.0001)
maxgoal <- 6
resultprob <- rep(0, length(Xi))
startdate <- england_2011_12$Date[1]
for (u in 1:length(Xi)){
for (i in 1:19) {
currentdate <- as.Date(startdate)+i*14
filter(england_2009_12, as.Date(Date) %
mutate(home=as.character(home), visitor=as.character(visitor)) -> dates
myweights <- DCweights(as.Date(dates$Date), currentdate, xi=Xi[u])
optim_res <- optim(par = unlist(parameter_list), fn=DCloglikweighted,
goals_home = dates$hgoal,
goals_visitor = dates$vgoal,
team_home = dates$home,
team_visitor = dates$visitor,
param_skeleton=parameter_list,
weights=myweights,
method = "Nelder-Mead", hessian = "FALSE")
parameter_estweight <- relist(optim_res$par, parameter_list)
parameter_estweight$defence <- c( sum(parameter_estweight$defence) * -1, parameter_estweight$defence)
names(parameter_estweight$defence)[1] = as.Date(currentdate), as.Date(Date) %
mutate(home=as.character(home), visitor=as.character(visitor)) -> games
if (length(games$Date)>=1){
for (j in 1:length(games$Date)){
lambda <- exp(parameter_estweight$home + parameter_estweight$attack[games$home[j]] +parameter_estweight$defence[games$visitor[j]])
mu <- exp(parameter_estweight$attack[games$visitor[j]] +parameter_estweight$defence[games$home[j]])
probability_matrix <- dpois(0:maxgoal, lambda) %*% t(dpois(0:maxgoal, mu))
scaling_matrix <- matrix(tau(c(0,1,0,1), c(0,0,1,1), lambda, mu, parameter_estweight$rho), nrow=2)
probability_matrix[1:2, 1:2] <- probability_matrix[1:2, 1:2] * scaling_matrix
ifelse(games$result[j] == "H", resultprob[u] <- resultprob[u]+log(sum(probability_matrix[lower.tri(probability_matrix)])),
ifelse(games$result[j] == "D", resultprob[u] <- resultprob[u]+log(sum(diag(probability_matrix))),
resultprob[u] <- resultprob[u] + log(sum(probability_matrix[upper.tri(probability_matrix)]))))
}
}
}
}
}
Hi,
Great posts! Would you be able to show code for calculating the ranked probability score please? I am currently using the Brier scores but it means calculating for win, loss and draw.
Thanks! I just posted the code as a proper blog post. Read it here:
http://opisthokonta.net/?p=1333
Hi,
first of all: great articles, very clear and straight to the point!
I tried to implement this last step of the model but I think I’m missing something. I calculate the weights outside the optimization function, and pass them as parameters inside par.inits. I think that by doing so I implicitly force the weights to be optimized too…
DCoptimFnWeighted <- function(params, DCm){
home.p <- params[1]
rho.p <- params[2]
nteams <- length(DCm$teams)
attack.p <- matrix(params[3:(nteams+2)], ncol=1)
defence.p <- matrix(params[(nteams+3):(2*nteams+2)], ncol=1)
weights <- matrix(params[(2*nteams+3):length(params)], ncol=1)
lambda <- exp(DCm$homeTeamDM %*% attack.p + DCm$awayTeamDM %*% defence.p + home.p)
mu <- exp(DCm$awayTeamDM %*% attack.p + DCm$homeTeamDM %*% defence.p)
return(
DClogLikWeighted(y1=DCm$homeGoals, y2=DCm$awayGoals, lambda, mu, rho.p, weights) * -1
)
}
the function DClogLikWeighted is the one you suggested.
Can you please tell me where I am wrong? How should I pass the weights to the LogLikWeighted function?
thank you
Thank you!
From the code you posted it seems like you try to optimize all the weights. In the model estimation the weights are treated as given, ie they are not to be estimated. If you try to minimize the negative weighted log-likelihood functions the weights will all be estimated to -Inf or something. That is why you should pass the weights you want to use (those calculated by the DCweights function, for example) directly to the likelihood function, and not treat them as parameters to be estimated. To find the optimal weights from the DCweights function I did what Dixon and Coles did in their paper: Emulate a real prediction situation where you try to predict the next match using the data available up to that point in time, and evaluate the prediction accuracy for different values of the dumping factor xi.
What would I pass into dates in the DCWeights function? I am new to R.
You should pass a vector of the Date class. You would typically have a character vector with dates, and you can convert this to a proper date vector with the as.Date() function.
Sorry, could you show how to do this in R? I am not able to do so.
Here is a quick example:
# Character vector with dates
my_dates <- c('2005-08-13', '2013-09-02') as.Date(my_dates)
Hi, I tried that but it is giving me the following error: Error in `-.Date`(dates, as.Date(currentDate)) :
can only subtract from “Date” objects
> Below is my current code.
my_dates <- c('2016-08-20', '2016-06-11')
as.Date(my_dates)
myweights <- DCweights(my_dates, xi = 0.0018)
return(
DClogLikWeighted(y1 = DCm$homeGoals, y2 = DCm$awayGoals, lambda, mu, rho.p, myweights) * -1
)
You need to pass the output from the as.Date function to a variable, or inside the function call argument. It could be like this:
my_dates <- c('2016-08-20', '2016-06-11') myweights <- DCweights(as.Date(my_dates), xi = 0.0018)
Hello,
First of all, I apologise for the late comment. Secondly, your posts have helped me a lot and I have made a similar model in Excel (I know Excel isn’t the best tool for this kind of stuff … however, I’m doing my A-Levels and it is what was easiest at the time since I have no coding experience/knowledge).
Could you clarify how exactly you calculate ? please? My spreadsheet is set up with a few seasons of results with corresponding dates but I am not too sure how I can find the value for ?.
Sorry if I sound stupid here, I only have basic knowledge compared to you guys as I start university later this year.
Thanks
Could
Im sorry, but it looks like some of your comment is missing. What is it that you don’t know how to calculate? The xi? The ranked probability score?
Hello,
I realised I added in a random word at the bottom somehow. Sorry for the confusion there!
The part I am struggling with is determining a value for ? in the following formula:
?(t)=exp(??t)
For my t I’m using says since last match. But as I’m working in Excel I can’t figure out how to get a value for ?.
Hope this clears it up, and thank you for your response.
The way I do it is for each match day, I fit the model for all available previous data, and predict the results on the games on that day. I do this for a couple of seasons, say. I do thins for several values of xi, and select the one that gives best predictions. This can take a few hours when I do it in R.
Hello,
Sorry for my late reply.
Thank you very much – that’s cleared everything up for me!
You’re welcome!
Hi, sorry but i don’t understand how you calculate the best value for xi. I try with doing a cicle where for every value of xi from 0.0001 to 0.02 (increasing by 0.0001), i get the estimates from the model, then i calculate the value of the PLL, but the PLL is always decreasing. Any suggestion? there is the code:
#function to create the thetea Home, draw, away
genThetadata$awayGoals]=1
if(t==”Draw”)
theta[data$homeGoals==data$awayGoals]=1
if(t==”Away”)
theta[data$homeGoals<data$awayGoals]=1
return(theta)
}
#function for estimate the probabilties
#p_match result return a vector with the pWin, pDraw, pLoss
genP<-function(data,mle)
{
k=length(data$homeGoals)
p=matrix(rep(1,(k*3)),nrow=k)
for(i in 1:k){
gen.p=p_MatchResult(mle,data,data$homeTeams[i],data$awayTeams[i])
p[i,1]=gen.p[1]
p[i,2]=gen.p[2]
p[i,3]=gen.p[3]
}
return(p)
}
S<-function(thetaHome,thetaDraw,thetaAway,p)
{
p.H=p[,1]
index=which(p.H==0)
p.H[index]=1
p.D=p[,2]
index=which(p.D==0)
p.D[index]=1
p.A=p[,3]
index=which(p.A==0)
p.A[index]=1
return(sum(thetaHome*log(p.H)+thetaDraw*log(p.D)+thetaAway*log(p.A)))
}
phi<-function(eta,data,ref.date=Sys.Date())
{
t=(as.numeric(ref.date-data$Date))
weight=exp(-1*eta*t)
weight[t<0]=0
return(weight)
}
….
if(weight)
{
s.val=NULL
xi=0
e=0.00001
tH=genTheta(data,"Home")
tD=genTheta(data,"Draw")
tA=genTheta(data,"Away")
while(es.val))
{
xi=e
s.val=s.val2
}
e=e+0.0001
}
optim=nlminb(par,logLik,data=data,phi=phi(xi,data))
hess=hessian(func=logLik,x=par,data=data,phi=phi(xi,data))
}
….
It will be very helpfull for me, i’m a student and i’m writing about this topic on my final review. Hope for reply, thank you.
Sorry there were an error in the code i posted before…
this is the main part: i maximezed the loglik function (it is sum(phi* logLikDixonColes) ) and the i calculate the S value (the PPL)
….
if(weight)
{
s.val=NULL
eta=0
e=0.00001
tH=genTheta(data,”Home”)
tD=genTheta(data,”Draw”)
tA=genTheta(data,”Away”)
while(es.val))
{
eta=e
s.val=s.val2
}
e=e+0.0001
}
optim=nlminb(par,logLik,data=data,phi=phi(eta,data))
hess=hessian(func=logLik,x=par,data=data,phi=phi(eta,data))
}
….
Sorry again when i post the comment it cut the main part of the code….
If the PPL is always decreasing it is probably because the optimal xi is greater than the greatest value you are trying.
Hi, first of all thanks for your work!
Can you show how you calculate the xi optim value?
I tried wit doing 2 loop: One that just change the value of xi and in the inner loop I optimezd the model for each match day and calculate the probability of outcome, then with all the probability I calculate the value of the PPL.
But the series of PPL that I get is not regular, it is first increasing then decresing and again increasing and decreasing and so for all the range of value of xi I tried (about 0.0001 to 0.02).
Am I missing something?
They way you describe your procedure seems right, so my guess is that you have a introduced a bug somewhere, where you perhaps overwrite some results, or you index something wrong or something.
I checked my code but i’m still blocked. Is there any possibility you can show your code, please? it would be very helpfull
I don’t think that would be very helpful. There are so many possible way of doing this, the data could be coded in different ways, and so on, so code for doing this would not be very informative, I think.
Hey, was just wondering if the inclusion of the time weighting would influence the parameter calculations of if it is just in use for the predictions?
The time weights are only used in the parameter estimation. They are not used when calculating the predictions.
When I change the value of xi it doesn’t change the value of my parameter estimations? I’ve used your code
tau <- Vectorize(function(x, y, lambda, mu, rho){
if (x == 0 & y == 0){return(1 – (lambda*mu*rho))
} else if (x == 0 & y == 1){return(1 + (lambda*rho))
} else if (x == 1 & y == 0){return(1 + (mu*rho))
} else if (x == 1 & y == 1){return(1 – rho)
} else {return(1)}
})
DCweights <- function(prem15, currentDate, xi){
datediffs<-difftime(strptime(prem15$Date, format ="%d/%m/%y"), strptime(currentDate, format="%d/%m/%y"), units="days")
datediffs<-as.numeric(datediffs*-1)
w <- exp(-1*xi*datediffs)
w[datediffs <= 0] <- 0 #Future dates should have zero weights
return(w)
}
DClogLikWeighted <- function(x, y, lambda, mu, rho=0.06, weights=weights){
loglik<-sum(log(tau(x, y, lambda, mu, rho)) + log(dpois(x, lambda)) + log(dpois(y, mu)))
if(is.null(weights)){
return(sum(loglik))
}else{
return(sum(loglik*weights))
}
}
DCoptimFn <- function(params, DCm){
home.p <- params[1]
rho.p <- params[2]
nteams <- length(DCm$teams)
attack.p <- matrix(params[3:(nteams+2)], ncol=1)
defence.p <- matrix(params[(nteams+3):length(params)], ncol=1)
lambda <- exp(DCm$homeTeamDM %*% attack.p + DCm$awayTeamDM %*% defence.p + home.p)
mu <- exp(DCm$awayTeamDM %*% attack.p + DCm$homeTeamDM %*% defence.p)
return(
DClogLikWeighted(x=DCm$homeGoals, y=DCm$awayGoals, lambda, mu, rho.p, weights=weights) * -1
)
}
DCattackConstr <- function(params, DCm, …){
nteams <- length(DCm$teams)
attack.p <- matrix(params[3:(nteams+2)], ncol=1)
return((sum(attack.p) / nteams) – 1)
}
date<-"25/05/15"
weights<-DCweights(prem15, date, xi=0.5)
prem15DC<-DCmodelData(prem15)
#initial parameter estimates – make sure the length is the same prem thing
attack.p <- rep(0.01, length(unique(prem15DC$teams)))
defence.p <- rep(-0.08, length(unique(prem15DC$teams)))
home.p <- 0.06
rho.init <- 0.06
par.inits <- c(home.param, rho.init, attack.p, defence.p)
names(par.inits) <- c('HOME', 'RHO', paste('Attack', prem15DC$teams, sep='.'), paste('Defence', prem15DC$teams, sep='.'))
test<-auglag(par=par.inits, fn=DCoptimFn, heq=DCattackConstr, DCm=prem15DC)
Where prem15 is the 2014/15 season data, if I change the value of xi the parameters are the same?
What I mean is that when you multiply by the weights in the DCLogLikWeighted function, yes the resulting value will be lower in the Optim Function, but surely the same values for the paremeters will minimise this too?
The parameters should change when you change xi. In your code you have a large value of xi (0.5), so small changes is that might not change the parameter estimates much when you have data from only one season.
Apologies, the xi in there is incorrect to what I used, I have tried a loop from 0.01 to 0.06 using the code
date<-"25/05/15"
for(i in seq(0.001,0.04, 0.001))
{
weights15<-DCweights(prem15, date, xi=i)
test<-auglag(par=par.inits, fn=DCoptimFn, heq=DCattackConstr, DCm=prem15DC)
ActualResultsProbs(prem15) #This produces the value for the pll
}
and there are no changes to the parameters, they all produce for example 1.40 for Arsenal using the full 2014/15 season, simply outputting smaller fvals of the output of the auglag.
Any idea why it doesn't change?
It seems like you don’t actually pass weights15 to DCoptimfun via auglag.
I don’t understand why the output of the optim function would change as the weights change though? For example, when I use xi=0.001 I get an output once maximised of 216100, but when I use xi=0.005 I get 241200. However these use the same values for the parameters.
Im not sure i follow you. Do you think it is strange that a weighted sum changes as the weights change?
Hi,
I’ve been working through the blog posts and am struggling to implement the weights.
I don’t get any errors when I run the code but the results and the same as when I didnt have any weights. Do you mind checking my code? Also how do you create the plots at the top of this blog
Forgot to add code.
dates<-dta$Date
as.Date(dates)
DCweights <- function(dta, currentDate=Sys.Date(), xi){
datediffs <- dates – as.Date(currentDate)
datediffs <- as.numeric(datediffs *-1)
w <- exp(-1*xi*datediffs)
w[datediffs <= 0] <- 0 #Future dates should have zero weights
return(w)
}
myweights <- DCweights(as.Date(dates), xi=0.0018)
DClogLikWeighted <- function(y1, y2, lambda, mu, rho=0, weights=myweights){
#rho=0, independence
#y1 home goals
#y2 away goals
loglik <- log(tau(y1, y2, lambda, mu, rho)) + log(dpois(y1, lambda)) + log(dpois(y2, mu))
if (is.null(weights)){
return(sum(loglik))
} else {
return(sum(loglik*weights))
}
}
Have you made sure that the weights in myweights are sensible? Your Dcweights function seem to be changed from from my version (see the arguments). And the way you use it seems a bit strange. You only give it two arguments.
Hi,
Right now I´m implementing a few football models using time weight factors in the likelihood. The only thing I´m not sure about is, how long the period is over which I have to calculate the PLL for each Xi, and when has this period to be (ie, in the beginning of a season it will may give a different output then in the end of the season).
Nice work and website by the way! Keep up the good work.
Regards,
Matthias
Thanks! There is no definite answer, but I guess calculating ppl for the last three seasons should be ok. But this is just a guess. I think you have to consider how the optimal weighting may change over time, and how much data you should use to get a precise value of the weight parameter. It would be interesting to analyse this in more detail.
Thank you! I think the problem then is that the estimates of the teams in the first season aren’t well fitted (too little matches). What do you think about 2 seasons, starting from january (or 2 and a half, but then the data isn’t well distributed when it comes to the date of a match)? Because I run my programs in Matlab it will take some time (didn’t use any fitting for poisson regression or something), but I will let you know if it has succeeded!
Regards
To clarify what I meant, I think you should use as much data as possible (where the weights are not practically zero) in the actual model fitting, but consider the out-of-sample back-testing only for some of the more recent seasons. Since the optimal weighting to predict future matches might be different now than what was the case for 15 years ago, but it might still be value in including matches a couple of seasons back (with the appropriate weighting) in the actual model fitting. Hope this makes sense?
Great series of articles!! They help a lot!!Although I would appreciate your help in one issue. First of all I work on R . In addition I work with the complete time-weighted Dixon Cole Model. Here comes the tricky part…How can i add an another variable like shots on target ( and what code exactly ) .Thank you in advance!
Thanks! It is unfortunately not that easy to incorporate more predictors in the full model, at least not in the implementation I have posted here on this blog. It is much easier in the indirect model in Part 3, the glm function is used to add predictors.
Thank you for the great posts. Just starting out in R.
I was able to get the non weight model to run.
Trying to get the weighted version to work.
i’ve added.
dates<-dta$Date
myweights <- DCweights((dates), xi=0.0018)
DCweights <- function(dta, currentDate=Sys.Date(), xi){
datediffs <- dates – as.Date(currentDate)
datediffs <- as.numeric(datediffs *-1)
w <- exp(-1*xi*datediffs)
w[datediffs <= 0] <- 0 #Future dates should have zero weights
return(w)
}
DClogLikWeighted <- function(y1, y2, lambda, mu, rho=0, weights=myweights){
#rho=0, independence
#y1 home goals
#y2 away goals
loglik <- log(tau(y1, y2, lambda, mu, rho)) + log(dpois(y1, lambda)) + log(dpois(y2, mu))
if (is.null(weights)){
return(sum(loglik))
} else {
return(sum(loglik*weights))
}
}
and i'm getting this error
Warning messages:
1: In DCweights((dates), xi = 0.0018) :
Incompatible methods ("Ops.factor", "-.Date") for "-"
2: In Ops.factor(datediffs, -1) : ‘*’ not meaningful for factors
Would greatly appreciate any help
“I used data from the 2005-06 season and onwards, and did predictions from January 2007 and up until the end of 2014. I also skipped the ten first match days at the beginning of each season to avoid problems with lack of data for the promoted teams.”
Just to try and understand, you estimated the parameters from using data from season 2005-2006 until 2014, and your PLL predictions were from Jan 2007 onwards (so kind of like an in-sample forecast)?
Also, I was curious as to what transformation you used for converting the PLL between 0 and 1? Many thanks
I did not do in-sample-forecast. For each matchday, I used the data that would have been available up to that date, but no data older than from the 2005-06 season. The first predictions were from January 2007, so about 2 and a half season worth of data would be available at the beginning.
So it’s a type of out-of-sample forecast?
When you say you use the data that would have been available up to the matchday, do you mean that you re-estimate the model every matchday (trying different values for xi) using the data up to that matchday? If so, couldn’t you get different values of xi depending on the matchday?
The reason I’m asking is because I’m trying to fit the model to a different league and I’ve been getting very weird results for xi (although I’m doing an in-sample forecast) but it PLL seems to be increasing and I’m already at 0.3…
Yes, it is out-of-sample. Yes, the model is re-estimated for each match day. I think backtesting is what it’s called when you do this kind of cross validation in the context of time.
xi is not estimated on each match day, but kept constant. Xi is not a parameter as you would normally think of it, but a “tuning parameter”, that you have to guess using cross validation or backtesting or something.
How do you do the in-sample-forecast? If you use my DCweight function you have to specify the date where the weight become 1, and after that they are set to 0.
What I’ve been doing is I’ve been running the model with different values of xi, (from 0.001 to 0.009 by 0.001) then generating lambdas and mus for all the matches in sample, then creating a list of matrices of scores for each match, calculate win draw win probs predictions for each matrix in the list, and then calculate the PLL.
My challenge is that I’m using a different distribution to model the scores (not Poisson) and using a copula to capture dependency (if it exists). And it takes a while to run…
The problem with that approach is that you have some matches that have small weights during estimation, and these will therefore have little influence on the parameter estimates. So when you predict these in-sample you should not be surprised if you get poor results. In other words, I don’t think this is a good procedure for tuning xi.
I see that it will probably take some time to run. A potential speedup is to do a two step estimation, where you fit an ordinary Poisson model first, then with the estimated mus and lambdas, fit the copula model. I have tried this with the Dixon-Coles model and the results are pretty similar.
Sorry this is similar to the question I have just asked but to give context this method from Jay582 below is exactly how I’ve been doing it. How are you refitting the model each matchday without using the optim function? I have been setting each match day as ‘currentdate’ in your DCweights function and then recalculating the parameters using the optim function but obviously this is highly time consuming. But I don’t know a quick way of refitting the model every match day. Thanks in advance have really enjoyed all your blog posts!
Do you reckon that a different type of count distribution would yield similar results in terms of xi?
Yes, I think what type of distribution you use will only have a small impact on what xi is optimal.
Have you posted somewhere how to incorporate the time-weighted modification to the “simple re-implementation of the Dixon-Coles model from your blogpost dated May 6, 2018?
I looked but could not find anything on this.
No, i haven’t, but it is rather easy to do it, if you look at the code in this comment: http://opisthokonta.net/?p=1013#comment-6757
Its just a matter of multiplying the weights with each term in the (negative) log-likelihood (dc_negloglik() in the “simple implementation”) before you sum them.
Hi Jonas,
First of all, thank you very much for your work and for sharing your knowledge with us.
I have implemented a Poisson Model using you example http://opisthokonta.net/?p=296 and wondering if I can apply DCweights to it? I have a feeling it is possible because I see you can do it using your goalmodel package:
gm_res_w <- goalmodel(
goals1 = england_2011$hgoal,
goals2 = england_2011$vgoal,
team1 = england_2011$home,
team2=england_2011$visitor,
weights = my_weights
)
But I don't understand where to pass them. I thought I need to pass them to the glm function like this
glm(
goals ~ home + team + opponent,
family = poisson(link = log),
data = goal_model_data,
weights = my_weights
)
but it throws an error
Error in model.frame.default(formula = goals ~ home + team + opponent: invalid type (closure) for variable '(weights)'.
Could you please help me to understand how to use weights with the independent Poisson Model? Or it's only possible to do it with DC approach?
Thanks in advance!
It should absolutely be possible as you describe it. From the error message it might seem as if my_weights somehow is a function, and not a numeric vector. Could that be it? And also, have you made sure that you have “duplicated” the weights as you need to do when you fit the independent Poisson model with glm?
Hi Jonas,
indeed, I didn’t duplicate the weights, and that was the problem. Thanks for your help!