Predicting election outcomes has in the recent years been a popular activity among data analytics. I guess you all know how Nate Silver became known for his predictions in the United States elections. Next year is Norwegian election for parliament and I have been thinking about maybe making an attempt at predicting the results when that time comes. There are already some people in Norway doing this, like the pollofpolls.no website and the Norwegian Computing Center.
In the meantime I decided to take a look at some historical data. After each election in Norway a large survey (1500-2000+ respondents) is carried out in an attempt to figure out why people voted what they did. This has been going on since the 1950’s and includes both local and national elections. The data from the surveys are available online from the Norwegian Center For Research Data. Only raw data from the oldest surveys are available for immediate download, but the online analytics tool at the website can be used to create simple tabulations of the all variables in the raw data and the results can downloaded as spreadsheets.
The obvious thing to look at in data like these are if there are any correlations between voting patterns and demographic variables. Gender, income and geography are obvious ones, but they are pretty boring boring, so I didn’t want to look at those. Instead I decided to look at what the relationship between birth year and party preference were.
I used the online tool and tabulated year of birth (or age, if that was the only available) against which party each respondent voted and downloaded the raw numbers. I did this for each survey all the available national elections, and the local elections in this millennium. This gave data on 17 elections from 1957 to 2013. I then cleaned the data a bit, threw out the category of parties termed “others” (usually less than 2% of the votes), calculated the birth year from age where necessary, and a bunch of other small details. With 1500+ respondents, about 70 birth years in each election and about 7 parties gives about 3 to 4 respondents in each cell, on average. Some parties have much lower support, so these tend to have even lower counts. It was therefore necessary to aggregate the birth years into groups. After some experimenting, I ended up by grouping them in 7 year bins.
What makes birth year more interesting to look at than age is that it gives a window back in time. By looking at age only you get a range of ages from 18 to about 90, but when you look at this data from the birth cohort view you can see 150+ years back in time. The oldest respondent in the data set was born in 1865.
Okay, on to some plots. We can start out with the the support for the Labour Party which has been the most popular party in the time after WWII.

Each line in this plot is one election. The colors goes from black (the 1957 election) to red (the 2013 local election). We see that the general trend is that the Labour Party have most support among voters born before 1950, and that there is a decline among younger generations. We also see a trend where they are not as popular as they used to be in the 1960’s and 70’s, which is also seen in the generations born in the pre-1950’s cohorts. The dark red line at the bottom is the 2001 election, where the they did their worst election since the 1920’s.
So let’s take a look at the support for the Conservative Party, the second most popular party.

Unlike the Labour Party, there does not seem to be any generational trend at all. The Conservatives has usually received between 15-25% of the votes, except at a period in the 1980’s, where they received 30%.
The next party up is the Progress Party, which is currently in a coalition cabinet with the Conservative Party. The first election they participated in was the 1973 election, so the birth year series don’t go as far back as the other parties.
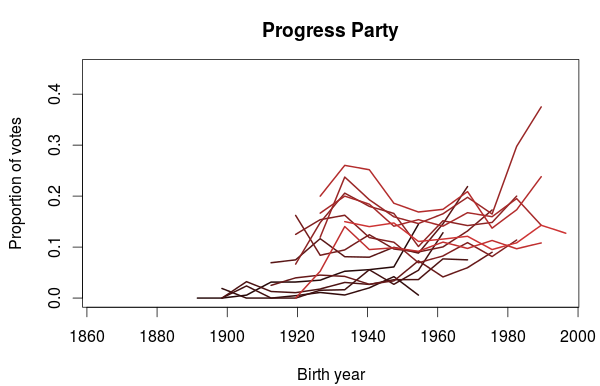
I think this plot is very interesting. It looks like the Progress Party is popular among people born in the 1930’s but also among the young voters. Notice how the rightmost part of each lines tend to point upwards. The 1930’s birth trend does not however seem to be present in the earliest elections (those with the darkest lines), but the popularity among the youngest part of the election cohort is there.
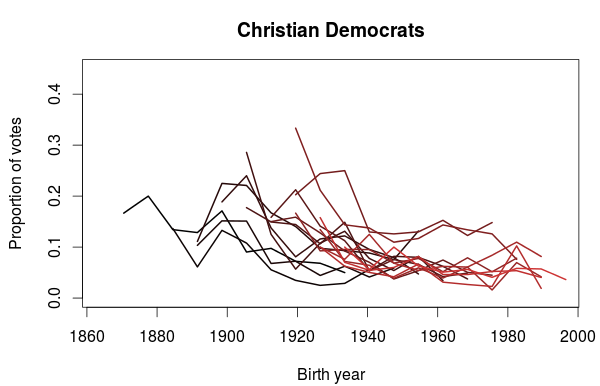
The support for the Christian Democratic Party also show some interesting trends. In the plot below we clearly see that they get a sizable portion of their votes from people born before 1940’s. Also noticeable are the two elections in the 1990’s where they did particularly well, where a lot of younger voters also voted for them. Does it also look like a small bump in popularity for voters born in the 1980’s? It could be just a coincidence, so it will be interesting to see if this appears in the next election as well.
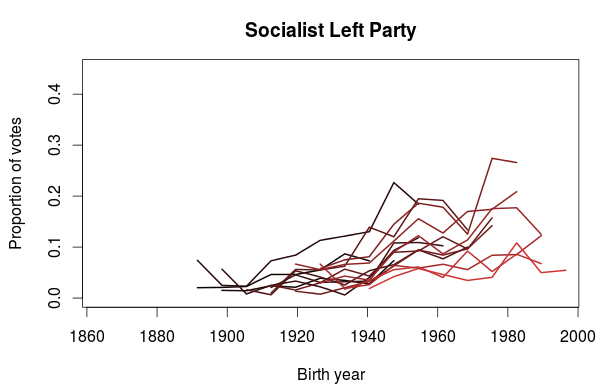
The last plot I want to show is for the Socialist Left Party. What this plot clearly shows is that the Socialist Party is more popular among the younger generations than the older. This does not mean we can extrapolate this into future elections and predict an increased popularity. On the contrary, we also see that their decreasing popularity since their peak in 2001 also applies to the younger generations. One could speculate that some of the younger voters have left the Labour Party in favor of the Socialist Party, and that will be the topic in a future blog post.