
In the previous post I discussed some Poisson-like probability distributions that offer more flexibility than the Poisson distribution. They typically have an extra parameter that controls the variance, or dispersion. The reason I looked into these distributions was of course to see if they could be useful for modeling and predicting football results. I hoped in particular that the distributions that can be underdispersed would be most useful. If the underdispersed distributions describe the data well then the model should predict the outcome of a match better than the ordinary Poisson model.
The model I use is basically the same as the independent Poisson regression model, except that the part with the Poisson distribution is replaced by one of the alternative distributions. Let the \(Y_{ij}\) be the number of goals scored in game i by team j
\( Y_{ij} \sim f(\mu_{ij}, \sigma) \)
\( log(\mu_{ij}) = \gamma + \alpha_j + \beta_k \)
where \(\alpha_j\) is the attack parameter for team j, and \(\beta_k\) is the defense parameter for opposing team k, and \(\gamma\) is the home field advantage parameter that is applied only if team j plays at home. \(f(\mu_{ij}, \sigma)\) is one of the probability distributions discussed in the last post, parameterized by the location parameter mu and dispersion parameter sigma.
To these models I fitted data from English Premier League from the 2010-11 season to the 2014-15 season. I also used Bundesliga data from the same seasons. The models were fitted separately for each season and compared to each other with AIC. I consider this only a preliminary analysis and I have therefore not done a full scale testing of the accuracy of predictions where I refit the model before each match day and use Dixon-Coles weighting.
The five probability distributions I used in the above model was the Poisson (PO), negative binomial (NBI), double Poisson (DPO), Conway-Maxwell Poisson (COM) and the Delaporte (DEL) which I did not mention in the last post. All of these, except the Conway-Maxwell Poisson, were easy to fit using the gamlss R package. I also tried two other gamlss-supported models, the Poisson inverse Gaussian and Waring distributions, but the fitting algorithm did not work properly. To fit the Conway-Maxwell Poisson model I used the CompGLM package. For good measure I also fitted the data to the Dixon-Coles bivariate Poisson model (DC). This model is a bit different from the rest of the models, but since I have written about it before and never really tested it I thought this was a nice opportunity to do just that.
The AIC calculated from each model fitted to the data is listed in the following table. A lower AIC indicates that the model is better. I have indicated the best model for each data set in red.
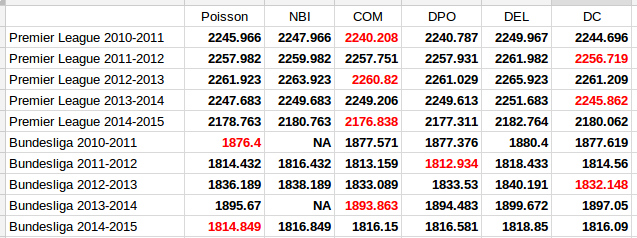
The first thing to notice is that the two models that only account for overdispersion, the Negative Binomial and Delaporte, are never better than the ordinary Poisson model. The other and more interesting thing to note, is that the Conway-Maxwell and Double Poisson models are almost always better than the ordinary Poisson model. The Dixon-Coles model is also the best model for three of the data sets.
It is of course necessary to take a look at the estimates of the parameters that extends the three models from the Poisson model, the \(\sigma\) parameter for the Conway-Maxwell and double Poisson and the \(\rho\) for the Dixon-Coles model. Remember that for the Conway-Maxwell a \(\sigma\) greater than 1 indicates underdispersion, while for the Double Poisson model a \(\sigma\) less than 1 is indicates underdispersion. For the Dixon-Coles model a \(\rho\) less than 0 indicates an excess of 0-0 and 1-1 scores and fewer 0-1 and 1-0 scores, while it is the opposite for \(\rho\) greater than 0.

It is interesting to see that the estimated dispersion parameters indicate underdispersion for all the data sets. It is also interesting to see that the data sets where the parameter estimates are most indicative of equidispersion is where the Poisson model is best according to AIC (Premier League 2013-14 and Bundesliga 2010-11 and 2014-15).
The parameter estimates for the Dixon-Coles model do not give a very consistent picture. The sign seem to change a lot from season to season for the Premier League data, and for the data sets where the Dixon-Coles model was found to be best, the signs were in the opposite direction of what where the motivation described in the original 1997 paper. Although it does not look so bad for the Bundesliga data, this makes me suspect that the Dixon-Coles model is prone to overfitting. Compared to the Conway-Maxwell and double Poisson models that can capture more general patterns in all of the data, the Dixon-Coles model extends the Poisson model to just parts of the data, the low scoring outcomes.
It would be interesting to do fuller tests of the prediction accuracy of these three models compared to the ordinary Poisson model.
About the DC model. If you look at parameter rho and define a confidence interval. What is your conclusion?
Here is a table of 95% confidence intervals:

The only data set where it is significant is the 2012-13 Bundesliga. I am not sure what to conclude, but I dont’t think an insignificant parameter estimate is all that interesting in this situation. The DC model may still provide better predictions than the Poisson model.
You can omit the parameter if the confidence interval contains the 0. Since it is not significant different from 0. With the parameter you would add more noise to the model.
I coded the DC in two totally different ways. Using the derivative and my rho’s are close together and they are always negative.
How strange. I compute the gradient numerically using the numDeriv package. Do your maximized log likelihood differ much between your two implementations?
I coded two bayesian network models, one of JAGS and the other one in STAN. Further did the derivative by hand and checked it via fmincon solver in MATLAB. I rearranged also the rho parameter. Lastly I run into slight precision problems; thus I did a QR-factorization beforehand. I don’t think a solver is the best way. I think a IRLS algorithm of http://bwlewis.github.io/GLM/ is.
I did not compare the log-likelihoods, since the Bayesian way is different(!), although it would be easily possible by little additional code.
A few comments/questions in no particular order:
I think to call Dixon-Coles a “bivariate” Poisson model is a bit misleading, there’s no lambda3 term in their model to account for the covariance directly. The DC model is really an independent Poisson model with inflation (or deflation) on [0,0] and [1,1] scores, and deflation (or inflation) on [1,0] and [0,1] scores.
Looking at the AIC values in the first table, overall there seems to be little significant difference among the models. For example, for the 2011/12 EPL season, an AIC of 2258 for Poisson vs an AIC of 2256.7 for DC corresponds to a relative likelihood of the Poisson model minimizing the information loss of exp((2256.7-2258)/2)=0.52. I’d want that ratio to be below 0.05 before concluding that the DC model is significantly better.
In table 2, can you explain how it is that these models are “finding” so much underdispersion? Referring to the incomparable engsoccerdata set, I find only 12 years out of the last 117 in the English 1st tier with underdispersed raw goal data, 14/51 years in the German 1st tier, 9/83 years in the Italian first tier, and 11/83 years in the Spanish 1st tier, although the frequency of underdispersed seasons seems to be increasing recently: 4 out of the last 20 years in England, 9 of the last 20 in Germany, 7 of the last 20 in Italy, and 5 of the last 20 in Spain.
I don’t think it is misleading to call it “bivariate” as it actually is two-variable distribution. Any model distribution with in two variables are bivariate, even a simple two-independent-Poissons-model (although it is not a particularly interesting model). But I agree that it can be misleading in the sense that it is not “the bivariate Poisson” that you think of, and the correlation structure in the DC model is only limited to small parts of it’s domain.
Yes I think the increase in fit is only moderate, and would probably not reject a null hypothesis of no increased fit. I know there are some different opinions on how the AIC should be interpreted and so on, but this was mostly a preliminary check to see if these models could have some potential, which I think this analysis show. In a realistic prediction setting I would have used data from several seasons and weighted the data using the Dixon-Coles method. I have yet to try this. More generally I think that models like these, which are more flexible in an important way with few extra parameters, should be used more. If the extra flexibility is not needed the model will naturally adapt to that.
I also tried to plot how the distributions looked with the estimated underdispersion compared to the Poisson. It was not much. I will try to put it up during the weekend.
The explanation for finding the underdispersion is that the models condition on which teams play each other (and which team play at home). The reason you see more variability in the raw, unconditioned, data is because it is an aggregate over many games, each of which you would think have its own expected number of goals. If each match has Poisson-distributed number of goals, where the expected values are gamma distributed, the aggregate distribution would be a negative binomial.
For me, an independent Poisson model is two univariate models, and bivariate models are reserved for those that explicitly account for the covariance of the variables. This nomenclature has been standard in the literature at least since Maher (1982). Even with the DC adjustment, the marginal distributions in their model are still independent Poisson. But we can agree to disagree 🙂
As for the under-dispersion question, if I condition say the 2012/13 EPL season goal totals on team and home/away, I find that some teams are over-dispersed, some under (an equal number of each, in fact) , but the mean dispersions home and away are still over-dispersed, as are most of the mean dispersions by team. So I am still confused where the overall under-dispersion in your models is coming from. If you condition on each team vs each opponent home and away, then you only have 1 data point for each condition each season, so that can’t be the explanation. Not sure this is going to work, but I will attempt to attach my table of the conditioned EPL 2012/13 table at the bottom of this post.
team hdp vdp mean
Arsenal 1.90 0.98 1.39
Aston Villa 1.71 1.05 1.31
Chelsea 1.61 1.39 1.52
Everton 0.37 1.13 0.92
Fulham 1.16 0.85 1.13
Liverpool 1.59 0.72 1.77
Manchester City 0.58 0.98 1.05
Manchester United 0.57 1.13 1.44
Newcastle United 1.04 1.12 1.06
Norwich City 0.93 0.74 0.91
Queens Park Rangers 0.98 1.37 0.97
Reading 1.06 0.90 1.05
Southampton 0.91 1.27 1.09
Stoke City 0.89 1.22 0.84
Sunderland 0.79 1.12 1.00
Swansea City 1.16 0.53 1.14
Tottenham Hotspur 0.61 2.07 1.39
West Bromwich Albion 0.86 0.84 1.03
West Ham United 0.78 1.57 0.82
Wigan Athletic 0.67 1.01 0.97
mean 1.01 1.10
Sorry, my mistake. Here is a corrected table of the conditioned 2012/13 EPL data:
home hdp vdp mean
Arsenal 1.90 0.98 1.44
Aston Villa 1.71 1.05 1.38
Chelsea 1.61 1.39 1.50
Everton 0.37 1.13 0.75
Fulham 1.16 0.85 1.00
Liverpool 1.59 0.72 1.15
Manchester City 0.58 0.98 0.78
Manchester United 0.57 1.13 0.85
Newcastle United 1.04 1.12 1.08
Norwich City 0.93 0.74 0.84
Queens Park Rangers 0.98 1.37 1.17
Reading 1.06 0.90 0.98
Southampton 0.91 1.27 1.09
Stoke City 0.89 1.22 1.06
Sunderland 0.79 1.12 0.95
Swansea City 1.16 0.53 0.84
Tottenham Hotspur 0.61 2.07 1.34
West Bromwich Albion 0.86 0.84 0.85
West Ham United 0.78 1.57 1.18
Wigan Athletic 0.67 1.01 0.84
mean 1.01 1.10
I am not sure I understand. What is hdp and vdp?
hdp = home dispersion parameter, i.e. 1.90 is the variance of Arsenal’s goals scored at home divided by the mean of Arsenal’s goals scored at home
similarly,
vdp = visitor dispersion parameter, i.e. 0.98 is the variance of Arsenal’s goals scored away divided by the mean of Arsenal’s goals scored away.
The marginal means (the last column and row) for each team, and for home and away, seem to indicate that even the conditioned data are over-dispersed (more values > 1.0 than < 1.0).
The regression model calculates the expected number of goals for each game a bit differently than what calculating the mean number of goals for each team does. The number of goals Arsenal expects to score in a game is not just estimated by the mean of goals scored, but it also takes into account who the current opponent is. The dispersion parameter is estimated with this in mind for all games in the season. This will give a different picture than just looking at the teamwise average number of, and variance of, goals.
Pingback: Putting the model to the test: Game simulation and Expected Goals vs. the betting market | Take The Shot
Hi!
Nice blog! I have a quick question. From the CompGLM package, what did you use? Did you use dcomp and write the likelihood/optimization yourself? Or did you use the GLM.comp function? If so, how did you implement this?
Thank you! I just used the glm.comp function from the CompGLM package.
I’ve been looking at the “problem” of whether or not Arsenal has a bad “November”. The data is EPL, League Cup, FA Cup and UEFA. One idea was that Arsenal played tougher opposition in November, I’m not seeing that. It seems likely that Arsenal tends to play the most games (least rest between games) at about the period in question. But the difference in games per unit time over the rest of the season is small. Most people “know” that Christmas is the busy period, but that is only true if you restrict yourself to EPL games only.
You think you are seeing under-dispersion. You and others (statisticians) talk about under dispersion and over dispersion, without connecting it to the data. What would cause under dispersion? What would cause scoring to have less variance than you are expecting?
One factor which can cause scoring different from expected, and has been seen in some leagues, is collusion. Team A and team B get more points over the season, if A wins at home to B and B wins at home to A, than if A and B tied in both home/away games.
You could also look into Calciopoli (however it is properly spelled) in Italy. There should be some evidence around, as it was in the courts for a while.
Are you seeing those, or similar types of things happening in the leagues you’ve been analysing (EPL and Bundesliga)? Are other people on the Internet seeing them? What is their evidence?
One of these days I will have to learn R, I tend to do most things in Perl.
I have looked at the effect of a busy schedule before and found some effect, but haven’t analyzed the last seasons. My guess would just be that Arsenal was unlucky. That can happen!
I do connect the underdispersion to the data! As you can see, the AIC values all indicate better fit and the parameter estimates, based on real data, all show underdispersion. I have been thinking about going deeper into what causes the underdispersion, for example by modeling the waiting times between the goals directly.
I model goals, not points, so the collusion you talk about couldn’t be a good explanation.
I haven’t really looked into fixing and cheating, and I am not sure how I would go about analyzing it. Any ideas what to look for?
Hi,
Could you put on line a COM script ?
You can try to use the CompGLM package I link to. It is fairly easy to use if you have used the built-in glm function before. There are a few other packages out there, but I haven’t gotten them to work.
Hello,
Sorry but I have difficulties to fit the Conway model using the CompGLM package.
I’m not sure how to feed the function glm.comp(lamFormula, nuFormula = NULL, data, lamStart = NULL, nuStart = NULL, sumTo = 100L, method = “BFGS”, …) for a particular league. Could you provide us a line of code that you would have used to produce your results and how would it be possible to predict the expGoal or Over/Under
Thank you
I’m not sure what your problem is. Could you please elaborate? If you follow the procedure two blog posts about the regular poisson model, it should be no problem using the glm.comp instead of the glm function.