
I recently read an interesting paper called The Betting Odds Rating System: Using soccer forecasts to forecast soccer by Wunderlich and Memmert. In their paper they develop av variant of the good old Elo rating system. Instead of using the actual outcomes of each match to calculate the ratings, they use the probabilities of the outcomes, which they get from bookmaker odds.
I was wondering if a similar approach could be used together with the goalmodel package I released a couple of months ago. The models available in the package are models I have written about extensively on this blog, and they all work as follows: You use the number of goals scored to get some ratings of the goal scoring and goal conceding rates of each team. You then use these ratings to forecast the expected number of goals in the upcoming games. These expected goals can then be used to calculate the probabilities of the outcome (Home win, draw, away win). A crucial step in these calculations is the assumption that the number of goals scored follow the Poisson distribution (or some related distribution, like the Negative Binomial).
But can we turn this process the other way around, and use bookmaker odds (or odds from other sources) to get expected goals and maybe also attack and defense ratings like we do in the goalmodel package? I think this is possible. I have written a function in R that takes outcome probabilities and searches for a pair of expected goals that matches the probabilities. You can find it on github (Edit: The function is now included in the goalmodel package.). This function relies on using the Poisson distribution.
Next, I have expanded the functionality of the goalmodel package so that you can use expected goals for model fitting instead of just observed goals. This is possible by setting the model argument to “model = ‘gaussian'” or to “model = ‘ls'”. These two options are currently experimental, and are a bit unstable, so if you use them, make sure to check if the resulting parameter estimates make sense.
I used my implied package to convert bookmaker odds from the 2015-16 English Premier League into probabilities (using the power method), found the expected goals, and then fitted a goalmodel using the least squares method. Here are the resulting parameters, from both using the expected goals and observed goals:
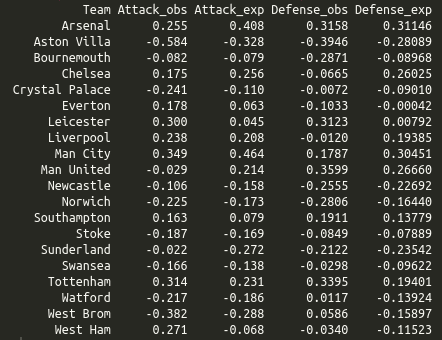
I wanted to use this season for comaprison as this was the season Leicester won unexpectedly, and in the Odds-Elo paper (figure 6) it seemed like the ratings based on the odds were more stable than the ones based on the actual results, which increased drastically during the season. In the attack and defense ratings from the goalmodels we see that Leicester have average ratings (which is what ratings close to 0 are) in the model based on odds, and much higher ratings based on the actual results. So the goalmodel and Elo ratings seem to agree, basically.
I also recently discovered another paper titled Combining historical data and bookmakers’odds in modelling football scores, that tries something similar as I have done here. They seem to do the same extraction of the expected goals from the bookmaker odds as I do, but they don’t provide the details. Instead of using the expected goals to fit a model, they fit a model based on actual scores (similar to what the goalmodel package do), and then they take a weighted average of the model based expected goals and the expected goals from the bookmaker odds.
The bookmakers don’t use the Poisson distribution. They use a variant. You may directly calculate the goal expectancy. For Home Team. 1 * p10 + 1 *p11 + 2 * p20 + 2 * p21 + …
where p10 is the probability to score 1:0, eg. 1 / ODD for 1:0.
The problems are
– high scoring ODDS, eg. 3:3 become unexact.
– the infinite sum p10 + p20 + p21 + … = p1 (Home win) is a sum of exponentials which cannot be solved analytically.
What sort of distribution do they use? If you had bookmaker odds for the different scorelines, then using the expectation formula would be the obvious choice. Here I only used information about the odds on the outcome (home, draw, away), which is why you need to make distributional assumptions.
I don’t know what distribution they are using. A bivariate poisson with diagonal inflation comes close.
I was disappointed about the bivariate negative binomial. Also copula’s didn’t worked out very well. I think no standard distribution will fit. So some tweaking will also we required. From the direct scoreline a reverse engineering with help of qqplot could lead to what they are using.
If you follow poisson p10 / p00 = 1.5 (the avg. home goal rate)
dpois(1,1.5)*dpois(0,1.1) / dpois(0,1.5) / dpois(0,1.1) = 1.5
(away goal rate vice versa).
If you do this with many odds, you’ll noice that the average of all
the rates above is off the average score rates in your selection, eg. 1.47
for english premiere league, etc.
The key is to find a mapping of the scores to the Win/Draw/Lose Odds.
There are many ways, if you log the score probablities, the ratios becomes differences, and thus able to use a PCA or LDA to extract the information.
x<-runif(1000,0.5,3)
y<-runif(1000,0.5,3)
X<-t(apply(cbind(x,y),1,function(x) dpois(0:5, x[1]) %o% dpois(0:5,x[2])))
p<-princomp(log(X))
cumsum(p$sdev) / sum(p$sdev)
# 3 scores enough
fit<-glm(x~p$scores[,1:3],family=poisson)
predict(fit,type="response") – x
fit<-glm(y~p$scores[,1:3],family=poisson)
predict(fit,type="response") – y
xp<-apply(as.matrix(x),1,function(x) rpois(1,x))
fit<-glm(xp~p$scores[,1:3],family=poisson)
predict(fit,type="response") – x
I don’t quite understand what your method is about. The method I posted was for extracting expected goals from the odds from a single game. If you try it out and take a look at the squared errors, you can usually see that the recovered expected goals almost perfectly matches the odds, using the Poisson distribution.
I used a direct poisson regression with score line odds (q00, q10,…) to predict the average number of goals.
Instead of fitting from the probability I log-transformed them.
To be exact I extracted the principal scores of the score line odds. And showed that only the components corresponding to the largest 3 eigenvalues are necessary to recover the original in the case of a poisson distribution.
bookies calculate correct score odds, and winning probs are derived from that. You don’t answer the most important question, where did they get all correct score probs?
using different regression methods or likelihood, like DC, or even machine learning you can figure out xG, and using a model you can derive any market you want (score based)
@opisthokonta excellent article once again
We have to see that bookies also provide in game odds. That means the distribution cannot be only just one which calculates the final result. It also must provide correct score probs at each time of the match.
The correct score odds are easy enough with two poisson distributions. Although I think its more a poisson birth/death process with a transitions matrix which allows to adjust for low goal rates.
Hello guys…how does expected goals works? How we read them to find out how many goals will be into a match? From example on understat at some teams is written +5.55 xG. Or negative one…what does it mean?
I suggest you contact the people behind understat for this question.
Hi Jonas very interesting method indeed ! I have just tried to repeat this procedure in Excel using bookmakers odds from last season for top 5 domestic completions ( so 1826 matches in total ). The problem is that using Poisson distribution leads to underestimate both expect goals home and away . When comparing to average goal actually scored I am always between -0.1 and -0.15 lower for all 5 leagues . Is that something you have noticed as well ? Any idea about why ?
I know others have noticed this, but I haven’t looked into this myself. I have compared the method here with a similar method for extracting the expected total goals from over/under 2.5 odds, and saw that over/under almost always had slightly greater expected total goals.
I have developed a method I am really happy with which you could maybe test whenever you get the time (and it might be worth a post for itself).
In short: we know that expected goal scored home and away are somehow correlated to bookmakers odds. This is indeed what you tested in your previous blog.
For each match we need the following information:
P1, PX, P2 (after removing overround) and Punder (probability of under 2.5).
Now comes the interesting part: if you calculate PHOME=P1+0,5*PX (similar to whta we do with ELo methods) you will see there is a very strong correlation between PHOME, PX and PUNDER.
So first you model PX and PUNDER as function of PHOME then you save the residuals. Those residuals are telling us how much more or less likely is that match to end in a draw and if there is an expectation for many or few goals.
Finally you run a Poisson regression using PHOME (up to the power of 4 or 5 gives the best results), Punder_residuals and PX_residuals to estimate goal scored.
The model can be further improved by taking into accounto other factors, but based on my analysis this is defintely the best way of addressing the problem. And if you calculate average goal scored home and away with this method they match very well the actual goal scored. Let me know what you think
Hello Carli.
Can you please give an example based on real odds and probabilities from any bookmaker available?
Lorenzo bookmakers’ odds are based on their estimation on expected goals per team/ match.
I am not sure what you are trying to achieve here
Hi! I noticed that there is no relationship between results and bookmaker odds (only in some cases). Bookmakers sometimes know in advance that the favorite will lose. But they cannot give the correct odds for this match, because the expectations of the crowd are completely different
Could you please elaborate what you mean by no relationship? Are the bookmaker odds xG completely uncorrelated to the actual results?
Hi Lorenzo,
Would you be willing to share your spreadsheet. Would like to have a look at this also?
Hi everyone! I can substract expected goals by bookies from their odds, but cant imagine how to use this data. Maybe you will give me some ideas yo work with.
How do you do that?
Hi Jaren, can you share the model or formula?
If there is a link, please share.
Hi, i really learn a lot from your articles. Thanks for you. The “imply” package is unavailable currently. Is there something wrong about it?
I took it down from github since I wanted to put it on CRAN. It took a bit longer than expected, but it is available now https://cran.r-project.org/package=implied
Hi
Great article. Would love to see a bit more about how you get from expected/observed goals values to attack and defence ratings. I can’t work out how you do this using least squares method
Thanks!
I have basically used the model I have described in this blog post, except that I have used a gaussian model (aka least squares) instead of the Poisson model. The reason is that the poisson model only works for counting-variables (non-negative integers), not decimal numbers like expected goals. I also used my goalmodel package to fit the model, and it is fairly well described on the github page. Other than that the setup is more or less the same.
Hi. Really interesting article. Just not sure how you are able to extract attack and defence ratings from expected goals values using least squares. Could you elaborate on how you did this?
Thanks
Thanks very much for your blog and packages. I’ve recently moved from modelling in excel to using R, and as I get a bit more hands on with R a lot of what I’ve read in your blog beings to make more sense to me as I r-read it.
Today I’ve finally reached by initial aim which was to genrate predictions where the attack and defence ratings are based on posterior xG values from previous matches (thanks to understat) rather than match results. The ability to model with decimal values for goals was invaluable as that was going to be my main issue.
Hi.
Great article. Could you please describe a little bit more how you get expected goals from probabilities? For example if we have 50%-20%-30% for H-D-A, what should we do next? As I understood the Poisson distribution is being used for that somehow, but how exactly? Unfortunately I’m not familiar with R and cannot understand what was done in your code
The method is quite simple. From a pair of expected goals you can compute the H-D-A probabilities using the Poisson. In this post there is some code to do this, and it is basically this approach I have used in the scripts as well. To go from from H-D-A probabilities to expected goals, I just search for the pair of expected goals that matches the H-D-A probabilities as much as possible (using squared errors).
You need one more source market, something like over under goals. Also the simple double poisson model does a poor job in controlling draws, so you need a model like bivariate poisson or dixon coles introducing one more variable.
Getting expected goals from over/under using a Poisson model is actually pretty easy. Maybe I should write a post about it?
Please do
Using overs and unders would be a new direction for me
You can read all about it in my latest update: http://opisthokonta.net/?p=1835
Good afternoon.
I managed to find the expectation of goals, for football, considering the market odds for Goals, considering Over / Under 2.5 and DNB (or Handicap 0), I am using PINNACLE closing Odds. However I was unable to find “use” for this, does anyone have any idea how to use it? Simply play in a Poison?
Hi, I see you’ve used a normal distribution to fit the expected goals implied from the bookmakers odds (since continuous distributions like Poisson can’t be used). I’ve been analysing and playing around with xG lately (to clarify, I’m talking about the shot-based models done by companies like Opta and Statsbomb, not the expected goals you derive from the bookmakers here) and thinking how some predictions could be made from them. A lot of the football modelling literature that exists (and that I’ve read) is based on actual observed goals and so the discrete distributions they discuss are inapplicable to generating team strengths when we’re working from continuous variables, as you do here. Since this kind of relates to what I’ve been doing recently I thought I could ask you some questions.
Considering that normal distribution in the log likelihood function – are you estimating the sd of the gaussian as a parameter for maximizing the log likelihood? If so can that sd be reasonably expected to be the same for all teams, no matter their mean expected goals?
Most importantly, can the normal distribution, with its characteristic 0 skewness, be proven to be an acceptable fit? Some of the preliminary analysis I’ve done seems to point to a better fit being found with a Gamma function (with rate = 2), and I suspect that there could be some EVA distributions that fit even better. Any thoughts you have on this, or any papers you can point me to? Thanks.
There is only one parameter for the standard deviation, and it will therefore be the same for all teams and for all predicted/fitted values. In the goalmodel package the gaussian model has a log-link function, which differs from standard linear regression, but is the default for Poisson regression models. It might very well be that a gamma distribution will fit better to Xg data, and it seem splausible that the residuals mught be a bit skewed, since the goals themself (and the Poisson used to model them) are also skewed.
The idea behind having the gaussian model is to model the expected values, and for that the gaussian model should be good enough (as in ordinary linear least squares regression, which is often good at modelling expected values even if the residuals are not Gaussian). The predict methods does not use the gaussian for predictions, but switches to the Poisson distribution if you try to predict using a model fitted with the Gaussian. This is because the aim of the package is to model goals, which are integers, not xG, which are continous. That said, you can still use the goalmodel package to fit models and do some additional modelling using the residuals etc. I don’t know of any papers doing this type of modelling on xG.
Experiments with sports prediction models. It starts from a multiplicative expected goals model, then it computes the odds for home draw away markets in two different ways, and then compare the performance of these odds to the bookmakers’ odds.