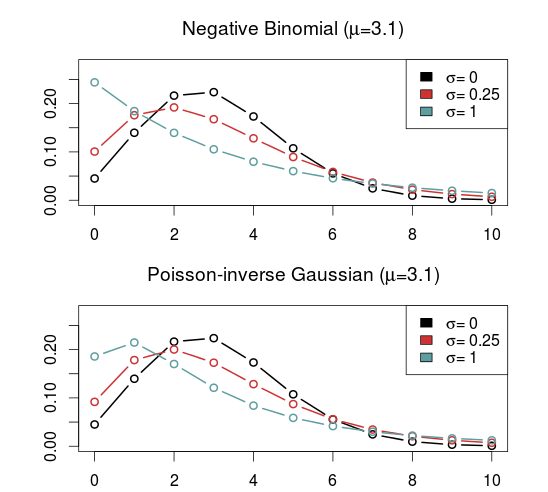
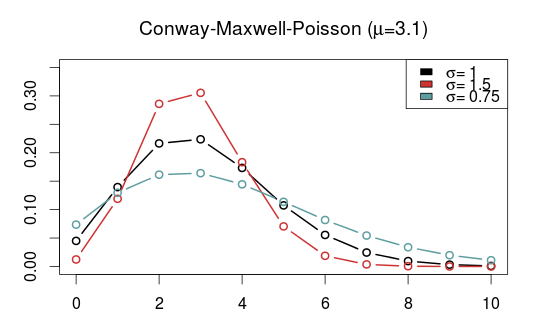
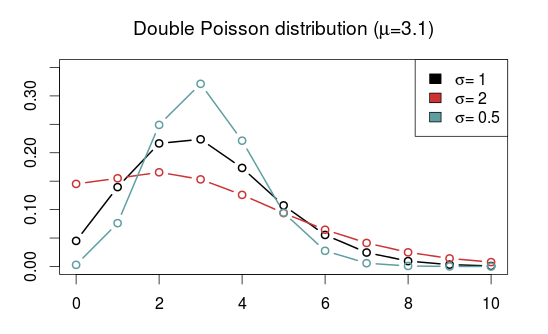
In the previous post I discussed some Poisson-like probability distributions that offer more flexibility than the Poisson distribution. They typically have an extra parameter that controls the variance, or dispersion. The reason I looked into these distributions was of course to see if they could be useful for modeling and predicting football results. I hoped in particular that the distributions that can be underdispersed would be most useful. If the underdispersed distributions describe the data well then the model should predict the outcome of a match better than the ordinary Poisson model.
The model I use is basically the same as the independent Poisson regression model, except that the part with the Poisson distribution is replaced by one of the alternative distributions. Let the \(Y_{ij}\) be the number of goals scored in game i by team j
\( Y_{ij} \sim f(\mu_{ij}, \sigma) \)
\( log(\mu_{ij}) = \gamma + \alpha_j + \beta_k \)
where \(\alpha_j\) is the attack parameter for team j, and \(\beta_k\) is the defense parameter for opposing team k, and \(\gamma\) is the home field advantage parameter that is applied only if team j plays at home. \(f(\mu_{ij}, \sigma)\) is one of the probability distributions discussed in the last post, parameterized by the location parameter mu and dispersion parameter sigma.
To these models I fitted data from English Premier League from the 2010-11 season to the 2014-15 season. I also used Bundesliga data from the same seasons. The models were fitted separately for each season and compared to each other with AIC. I consider this only a preliminary analysis and I have therefore not done a full scale testing of the accuracy of predictions where I refit the model before each match day and use Dixon-Coles weighting.
The five probability distributions I used in the above model was the Poisson (PO), negative binomial (NBI), double Poisson (DPO), Conway-Maxwell Poisson (COM) and the Delaporte (DEL) which I did not mention in the last post. All of these, except the Conway-Maxwell Poisson, were easy to fit using the gamlss R package. I also tried two other gamlss-supported models, the Poisson inverse Gaussian and Waring distributions, but the fitting algorithm did not work properly. To fit the Conway-Maxwell Poisson model I used the CompGLM package. For good measure I also fitted the data to the Dixon-Coles bivariate Poisson model (DC). This model is a bit different from the rest of the models, but since I have written about it before and never really tested it I thought this was a nice opportunity to do just that.
The AIC calculated from each model fitted to the data is listed in the following table. A lower AIC indicates that the model is better. I have indicated the best model for each data set in red.
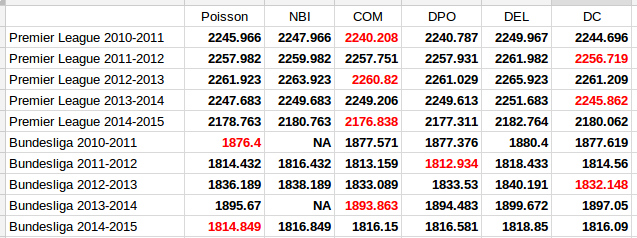
The first thing to notice is that the two models that only account for overdispersion, the Negative Binomial and Delaporte, are never better than the ordinary Poisson model. The other and more interesting thing to note, is that the Conway-Maxwell and Double Poisson models are almost always better than the ordinary Poisson model. The Dixon-Coles model is also the best model for three of the data sets.
It is of course necessary to take a look at the estimates of the parameters that extends the three models from the Poisson model, the \(\sigma\) parameter for the Conway-Maxwell and double Poisson and the \(\rho\) for the Dixon-Coles model. Remember that for the Conway-Maxwell a \(\sigma\) greater than 1 indicates underdispersion, while for the Double Poisson model a \(\sigma\) less than 1 is indicates underdispersion. For the Dixon-Coles model a \(\rho\) less than 0 indicates an excess of 0-0 and 1-1 scores and fewer 0-1 and 1-0 scores, while it is the opposite for \(\rho\) greater than 0.

It is interesting to see that the estimated dispersion parameters indicate underdispersion for all the data sets. It is also interesting to see that the data sets where the parameter estimates are most indicative of equidispersion is where the Poisson model is best according to AIC (Premier League 2013-14 and Bundesliga 2010-11 and 2014-15).
The parameter estimates for the Dixon-Coles model do not give a very consistent picture. The sign seem to change a lot from season to season for the Premier League data, and for the data sets where the Dixon-Coles model was found to be best, the signs were in the opposite direction of what where the motivation described in the original 1997 paper. Although it does not look so bad for the Bundesliga data, this makes me suspect that the Dixon-Coles model is prone to overfitting. Compared to the Conway-Maxwell and double Poisson models that can capture more general patterns in all of the data, the Dixon-Coles model extends the Poisson model to just parts of the data, the low scoring outcomes.
It would be interesting to do fuller tests of the prediction accuracy of these three models compared to the ordinary Poisson model.