In the previous blog posts about predicting football results using Poisson regression I have mostly ignored the fact that the data points (ie matches) used to fit the models are gathered (played) at different time points.
In the 1997 Dixon and Coles paper where they described the bivariate adjustment for low scores they also discussed using weighted maximum likelihood to better make the parameter estimates reflect the current abilities of the teams, rather than as an average over the whole period you have data from.
Dixon and Coles propose to weight the games using a function so that games are down weighted exponentially by how long time it is since they were played. The function to determine the weight for a match played is
where t is the time since the match was played, and \(\xi\) is a positive parameter that determines how much down-weighting should occur.
I have implemented this function in R, but I have done a slight modification from the one from the paper. Dixon and Coles uses “half weeks” as their time unit, but they do not describe in more detail what exactly they mean. They probably used Wednesday or Thursday as the day a new half-week starts, but I won’t bother implementing something like that. Instead I am just going to use days as the unit of time.
This function takes a vector of the match dates (data type Date) and computes the weights according to the current date and a value of \(\xi\). The currentDate argument lets you set the date to count from, with all dates after this will be given weight 0.
DCweights <- function(dates, currentDate=Sys.Date(), xi=0){
datediffs <- dates - as.Date(currentDate)
datediffs <- as.numeric(datediffs *-1)
w <- exp(-1*xi*datediffs)
w[datediffs <= 0] <- 0 #Future dates should have zero weights
return(w)
}
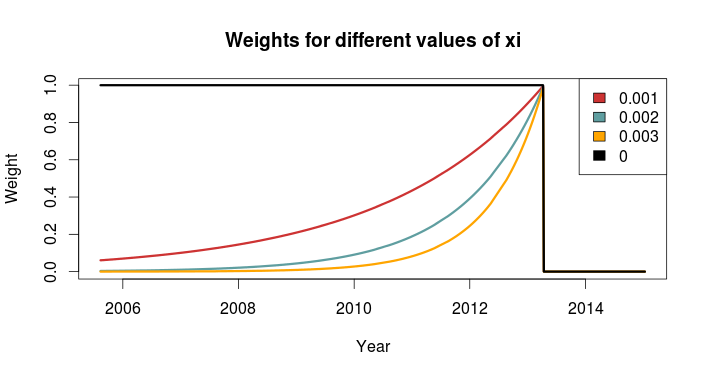
We can use this function to plot how the much weight the games in the past is given for different values of \(\xi\). Here we see that \(\xi = 0\) gives the same weight to all the matches. I have also set the currentDate as a day in April 2013 to illustrate how future dates are weighted 0.
To figure out the optimal value for \(\xi\) Dixon and Coles emulated a situation where they predicted the match results using only the match data prior to the match in question, and then optimizing for prediction ability. They don’t explain how exactly they did the optimizing, but I am not going to use the optim function to do this. Instead I am going to just try a lot of different values of \(\xi\), and go for the one that is best. The reason for this is that doing the prediction emulation takes some time, and using an optimizing algorithm will take an unpredictable amount of time.
I am not going to use the Dixon-Coles model here. Instead I am going for the independent Poisson model. Again, the reason is that I don’t want to use too much time on this.
To measure prediction ability, Dixon & Coles used the predictive log-likelihood (PLL). This is just the logarithm of the probabilities calculated by the model for the outcome that actually occurred, added together for all matches. This means that a greater PLL indicates that the actual outcomes was more probable according to the model, which is what we want.
I want to use an additional measure of prediction ability to complement the PLL: The ranked probability score (RPS). This is a measure of prediction error, and takes on values between 0 and 1, with 0 meaning perfect prediction. RPS measure takes into account the entire probability distribution for the three outcomes, not just the probability of the observed outcome. That means a high probability of a draw is considered less of an error that a high probability of away win, if the actual outcome was home win. This measure was popularized in football analytics by Anthony Constantinou in his paper Solving the Problem of Inadequate Scoring Rules for Assessing Probabilistic Football Forecast Models. You can find a link to a draft version of that paper on Constantinou’s website.
I used data from the 2005-06 season and onwards, and did predictions from January 2007 and up until the end of 2014. I also skipped the ten first match days at the beginning of each season to avoid problems with lack of data for the promoted teams. I did this for the top leagues in England, Germany, Netherlands and France. Here are optimal values of \(\xi\) according to the two prediction measurements:
| PLL | RPS | |
|---|---|---|
| England | 0.0018 | 0.0018 |
| Germany | 0.0023 | 0.0023 |
| Netherlands | 0.0019 | 0.0020 |
| France | 0.0019 | 0.0020 |
The RPS and PLL mostly agree, and where they disagree, it is only by one in the last decimal place.
Dixon & Coles found an optimal value of 0.0065 in their data (which were from the 1990s and included data from the top four English leagues and the FA cup), but they used half weeks instead of days as their time unit. Incidentally, if we divide their value by the number of days in a half week (3.5 days) we get 0.00186, about the same I got. The German league has the greatest optimum value, meaning historical data is of less importance when making predictions.
An interesting thing to do is to plot the predictive ability against different values of \(\xi\). Here are the PLL (adjusted to be between 0 and 1, with the optimum at 1) for England and Germany compared, with their optima indicated by the dashed vertical lines:

I am not sure I want to interpret this plot too much, but it does seems like predictions for the German league are more robust to values of \(\xi\) greater than the optimum, as indicated by the slower decline in the graph, than the English league.
So here I have presented the values of \(\xi\) for the independent Poisson regression model, but will these values be the optimal for the Dixon & Coles model? Probably not, but I suspect there will be less variability between the two models than between the same model fitted for different leagues.